HiveЕФМмЙЙКЭдРэ
HiveЪЧЛљгкHadoopЕФвЛИіЪ§ОнВжПтЙЄОпЃЌПЩвдНЋНсЙЙЛЏЕФЪ§ОнЮФМўгГЩфЮЊвЛеХБэЃЌВЂЬсЙЉРрSQLЃЈHQLЃЉВщбЏЙІФмЁЃHiveЪЧНЋHQLзЊЛЏЮЊMapReduceГЬађЃЌHiveДІРэЕФЪ§ОнДцДЂдкHDFSЩЯЃЌжДааГЬађдЫаадкYarnЩЯЁЃгЩгкжДааЕФЪЧMapReduceГЬађЃЌбгГйБШНЯИпЃЈЛЙгавЛИіживЊЕФдвђЪЧЃЌУЛгаЫїв§ЖјашвЊЩЈУшећИіБэЃЉЃЌвђДЫHiveГЃгУгкРыЯпЕФЪ§ОнЗжЮіЁЃ
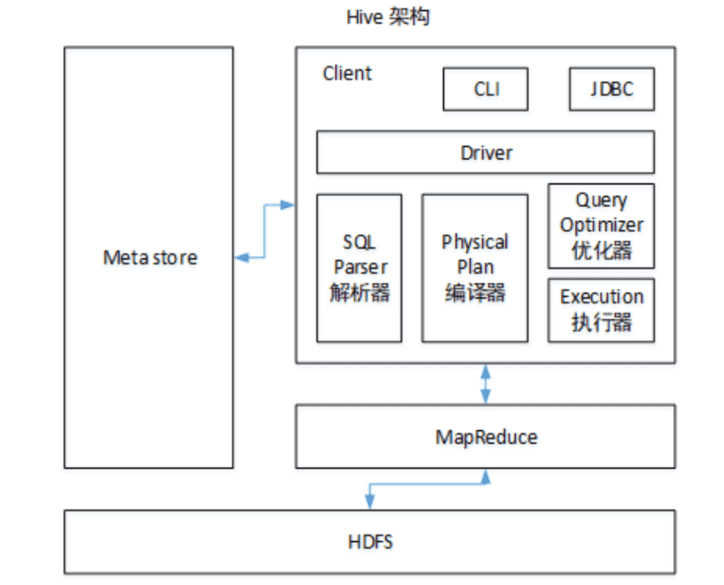
HiveМмЙЙЭМ
-
ClientЃКгУЛЇНгПк
CLIЃЈcommand-line interfaceЃЉЁЂJDBC/ODBCЃЈjdbcЗУЮЪhiveЃЉЁЂWEBUIЃЈфЏРРЦїЗУЮЪhiveЃЉ -
MetastoreЃКдЊЪ§Он
дЊЪ§ОнАќРЈБэУћЁЂБэЫљЪєЕФЪ§ОнПтЁЂБэЕФгЕгаепЁЂСа/ЗжЧјзжЖЮЁЂБэЕФРраЭЁЂБэЕФЪ§ОнЫљдкФПТМЕШЃЛФЌШЯДцДЂдкздДјЕФderbyЪ§ОнПтжаЃЌгЩгкПЊЦєЖрИіhiveЪБЛсБЈвьГЃЃЌЭЦМіЪЙгУMySQLДцДЂMetastoreЁЃ -
Hadoop
ЪЙгУHDFSНјааДцДЂЪ§ОнЃЌЪЙгУMapReduceНјааМЦЫуЁЃ -
DriverЃКЧ§ЖЏЦї
НтЮіЦїЃЈSQL ParserЃЉЃКНЋSQLзжЗћДЎзЊЛЛГЩГщЯѓгяЗЈЪїASTЃЌЖдASTНјаагяЗЈЗжЮіЃЌБШШчБэЪЧЗёДцдкЃЌзжЖЮЪЧЗёДцдкЃЌSQLгявхЪЧЗёгаЮѓЁЃ
БрвыЦїЃЈPhysical PlanЃЉЃКНЋASTБрвыЩњГЩТпМжДааМЦЛЎЁЃ
гХЛЏЦїЃЈQuery OptimizerЃЉЃКЖдТпМжДааМЦЛЎНјаагХЛЏЁЃ
жДааЦїЃЈExecutionЃЉЃКАбТпМжДааМЦЛЎзЊЛЏГЩПЩвддЫааЕФЮяРэМЦЛЎЃЌМДMapReduceЁЃ
HiveЭЈЙ§ИјгУЛЇЬсЙЉЕФвЛЯЕСаНЛЛЅНгПкЃЌНгЪеЕНгУЛЇЕФжИСюЃЈSQLЃЉЃЌЪЙгУздМКЕФЧ§ЖЏЦїЃЈDriverЃЉЃЌНЋSQLгяОфНтЮіГЩЖдгІЕФMapReduceГЬађЃЌВЂЩњГЩЯргІЕФjarАќЃЌНсКЯдЊЪ§ОнЃЈMetaStoreЃЉЬсЙЉЕФЖдгІЮФМўЕФТЗОЖЃЌЬсНЛЕНHadoopжажДааЃЌзюКѓНЋжДааНсЙћЪфГіЕНгУЛЇНЛЛЅНгПкЁЃ