云计算,大数据,人工智能
自己本身的方向并不是云计算,但在软件开发这个行业,很多工程师并不是单纯只研究自己的方向,即便不能切实的应用某项技术,前去了解也是一件很有意思的事情。在很多的公司,做为一个技术从业者,如果技术面很窄,可能会被同时diss,慢慢地,可能会没有朋友。最近了解了下云计算的一些知识,接下来谈谈我对于云计算的理解:
在了解云计算技术之前,先要知道云计算的目标:
云计算在设计之初,主要是为了对计算资源,网络资源,存储资源的管理
虚拟化:
我们先谈谈虚拟化技术:假如,我们花费100元在阿里云购买一台服务器,我们仿佛就获得了一台计算机,,我们想要使用远程工具登录到我们的计算机上进行相关的部署,而我们从阿里云购买的这台计算机,要知道只有100元,怎么可能买得到计算机呢?还要知道阿里云里面的每一台计算机在采购的时候都是非常昂贵的,但是我们就是花100元获得了计算机的使用权。这是怎么做到的呢?这里用到了虚拟化技术:
基于虚拟化技术的虚拟化软件可以创建一台虚拟的电脑,这台电脑提供电脑的所有的功能,但是你看不到其物体。这有点移动支付的味道,钱真实的到账了,但是你就是没有看到钞票。
实际上埃阿里云将一台台大型的计算机,划分成了一个又一个的小模块,客户的每一次购买,阿里云都是将数据中心的物理设备(计算机)虚拟出来一小块给客户,虚拟化的技术能够保证不同客户的电脑看起来是隔离的,比如我的100G是我的,你的100G是你的,但是实际上,这200G的存储在一块很大很大的磁盘上。
实现虚拟化最早的公司是VMware,VMware是闭源的,还有两个开源的虚拟化软件,Xen,KVM。使用虚拟化软件能够虚拟出来计算机,虽然虚拟化软件能够解决将一个大型机(更多是大型机集群)虚拟出多个计算机,供多人使用,但是虚拟化软件能够管理的集群规模有限制,一般不能很大(最多百台),而且一般的虚拟化软件创建一台虚拟机,需要人工指定这台虚拟电脑放在哪里。这里使用过VMware软件的应该知道,每一次新建虚拟机的时候,都必须要指定你的虚拟机放在哪个磁盘上。由于①人工,②管理的集群有限两个弊端,出现云化技术。
云化:
如果每一次虚拟出电脑,都需要去指定该电脑要放置的位置并做相应的配置,几乎是不可能的事情,我们需要将其机器化,自动化,人们发明了 各种各样的算法,算法的名字叫做Scheduler(调度)
就是说在数据中心里的物理机集群中,设置一个调度中心,这个调度中心管理整个数据中心的所有物理机,当用户提交计算资源的申请的时候,这个调度中心自动的处理用户的请求,虚拟出符号用户要求的计算机,并完成相应的配置,这个调度中心支持管理的服务器在万台,百万台。
这就是云化,可以理解为加强版的虚拟化技术,如果一个物理机集群,达到了云化的阶段,我们就可以称之为云计算了。
公有云,私有云:
云计算大致分为公有云和私有云,混合云为私有云和公有云的连接,我们这里不做讨论,所谓私有云:
①私有云:把虚拟化和云化的这套软件部署在别人的数据中心里面。使用私有云的用户往往很有钱,自己买地建机房、自己买服务器,然后让云厂商部署在自己这里
②公有云:把虚拟化和云化软件部署在云厂商自己数据中心里面的,用户不需要很大的投入,只要注册一个账号,就能在一个网页上点一下创建一台虚拟电脑。比如:AWS 即亚马逊的公有云;国内的阿里云、腾讯云
亚马逊为什么要做公有云呢?原来亚马逊是国外的一个较大的电商,国外的电商也有类似于国内的Double Eleven的场景,大家同一时刻,冲上去买东西,这是我们熟悉的高并发场景,需要巨大的计算资源支持,所以亚马逊需要一个云计算平台。当出现高并发的情况的时候,立马虚拟化一些计算机来应对高并发情况,过了高并发阶段,马上释放这些资源去做别的事情。
然而虚拟化软件太贵了,亚马逊不愿意掏这个钱,也不愿受制于虚拟化软件厂商,于是在开源虚拟化软件 Xen,KVM的基础上开发了自己的一套云化软件,后来亚马逊的云平台越来越牛。
虽然,亚马逊使用了开源的虚拟化技术,但是云化的代码是闭源的,很多公司看到亚马逊共有云很挣钱,但是苦于技术难度大投入大。后来,公有云的第二,Rackspace开放了云化的源代码,做云计算的公司纷纷涌入进来。
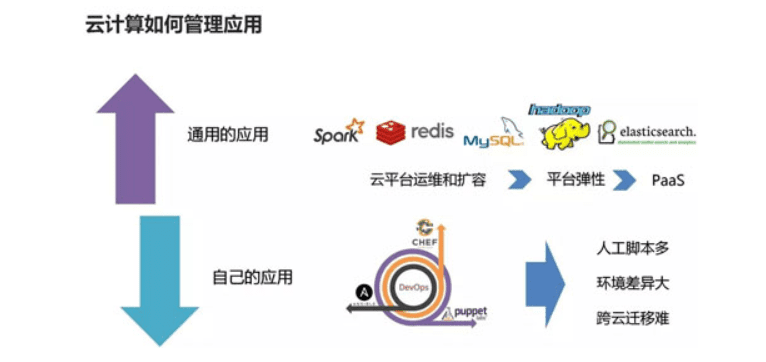
云计算的分层:Iaas,Pass,
计算、网络、存储我们常称为基础设施 Infranstracture,有了云计算之后,我们能够非常灵活的获取一台计算机(包含计算,网络,存储资源)因此云计算做到了基础即服务,而且这个服务还具有弹性,不使用的时候释放,使用的时候创建, 这个阶段的弹性称为资源层面的弹性。
IaaS 平台之上又加了一层,用于管理资源以上的应用弹性的问题,这一层通常称为 PaaS(Platform As A Service)。
docker容器技术:最大的应用就是在云计算的方向的Paas中,实现用户应用的在多台机器的部署,是实现自动化部署用户应用的工具。
PaaS层的作用:完成用户个性化应用的自动部署,通用的应用服务不用部署(实际上是云平台帮你部署了)
在PaaS层用户如何完成个性化应用的快速部署? 使用的是容器的技术。也既保存镜像和还原镜像。
这两步需要封闭的环境,封闭的环境有两个技术支持: 第一个隔离的技术,称为 Namespace,也即每个 Namespace 中的应用看到的是不同的 IP 地址、用户空间、程号等。 第二个隔离的技术,称为 Cgroups,也即明明整台机器有很多的 CPU、内存,而一个应用只能用其中的一部分
大数据和云计算之间的联系: 在PaaS层中一个通用的复杂的应用就是大数据平台, 数据没有用,但是数据里面有一个重要的东西,叫做信息,数据十分杂乱,经过梳理和清洗,才能够称为是信息,从信息中总结出规律出来,称为知识,知识应用于实践,就成了智慧。下面是图:
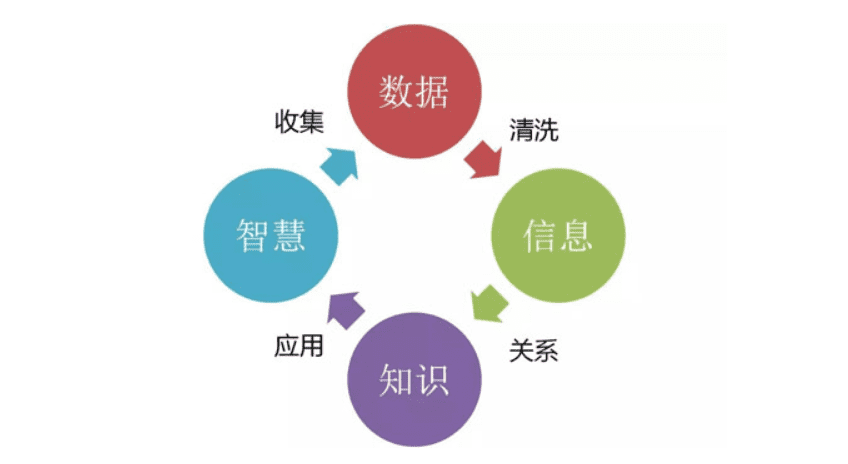
数据如何完成一次旅行?从数据到智慧?
- 数据收集
- 数据传输
- 数据存储
- 数据处理和分析
- 数据检索和挖掘
【数据收集】的方式有两种:
拿:抓取,或者是爬取,比如搜素引擎就是这么做的,它把网上的所有的信息都下载到它的数据中心,然后你一搜才能搜出来。比如你去搜索的时候,结果会是一个列表,这个列表为什么会在搜索引擎的公司里面?就是因为他把数据都拿下来了,但是你一点链接,点出来这个网站就不在搜索引擎它们公司了。比如说新浪有个新闻,你拿百度搜出来,你不点的时候,那一页在百度数据中心,一点出来的网页就是在新浪的数据中心了
推送,有很多终端可以帮我收集数据。比如说小米手环,可以将你每天跑步的数据,心跳的数据,睡眠的数据都上传到数据中心里面。 多台机器,完成数据的收集操作。
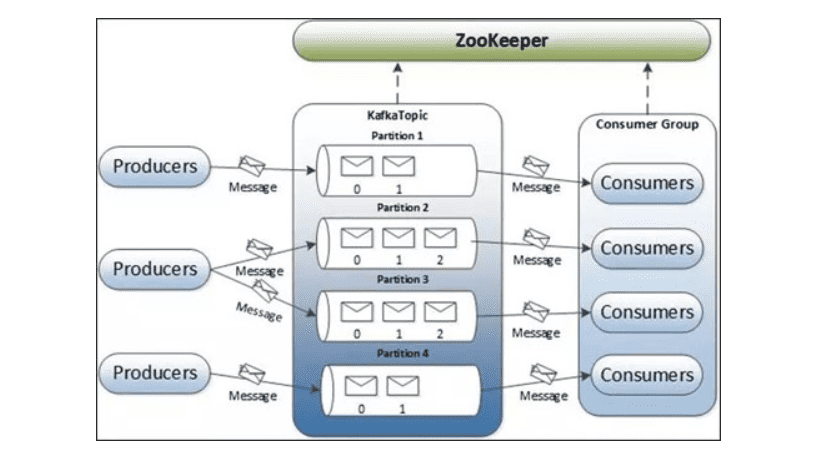
【数据传输】:一般会通过队列进行传输,因为数据量实在是太大了,系统处理不过来,只好排队,慢慢处理。这让我想到了kafka。 数据量非常大的时候,一个内存里面的队列一个内存里面的队列肯定会被大量的数据挤爆掉,于是就产生了基于硬盘的分布式队列,这样队列可以多台机器同时传输,随你数据量多大,只要我的队列足够多,管道足够粗,就能够撑得住
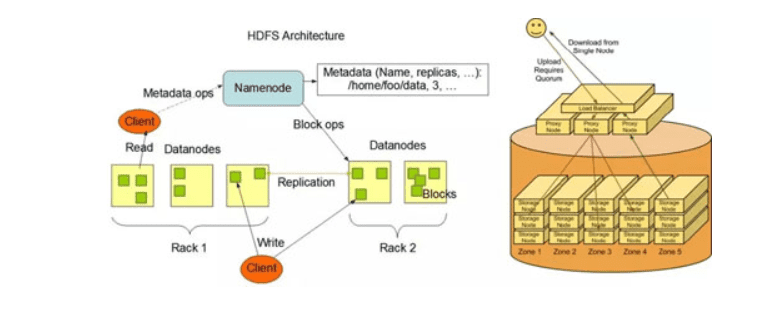
【数据存储】:这让我想到了HDFS,一台文件系统肯定是放不下的,所以需要一个很大的分布式文件系统:
数据处理和分析:原始数据杂乱无章,有很多垃圾数据在里面,需要清洗和过滤,这让我想起了MapReduce。terasort对一个TB的数据进行排序,单机处理需要几个小时,但是并行处理需要209秒。 数据量越来越大,很多不大的公司都需要处理相当多的数据,这些小公司没有那么多的机器怎么办?云计算来解决。
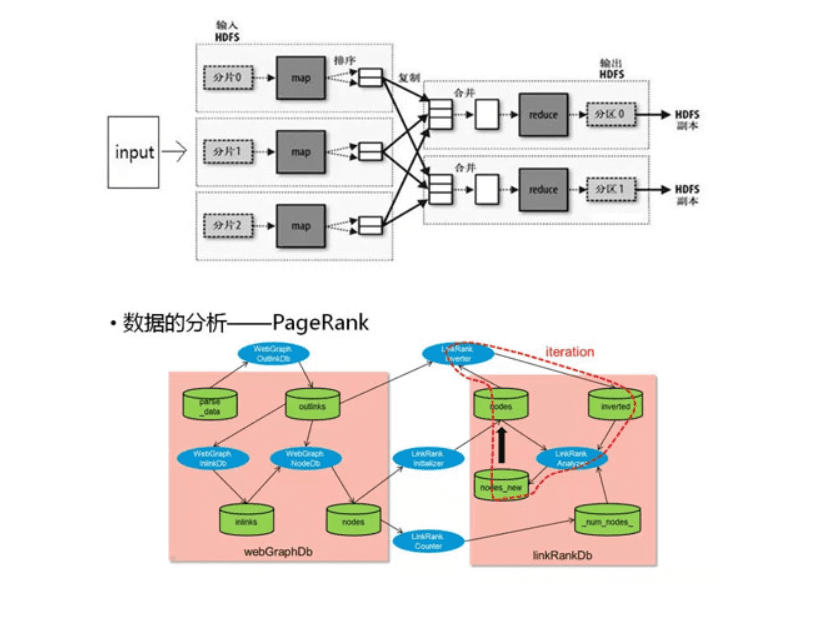
数据检索和挖掘:检索就是搜索,所谓外事不决问 Google,内事不决问百度。内外两大搜索引擎都是将分析后的数据放入搜索引擎,因此人们想寻找信息的时候,一搜就有了。另外就是挖掘,仅仅搜索出来已经不能满足人们的要求了,还需要从信息中挖掘出相互的关系。
比如财经搜索,当搜索某个公司股票的时候,该公司的高管是不是也应该被挖掘出来呢?如果仅仅搜索出这个公司的股票发现涨的特别好,于是你就去买了,其时其高管发了一个声明,对股票十分不利,第二天就跌了,这不坑害广大股民么?所以通过各种算法挖掘数据中的关系,形成知识库,十分重要。 数据量越来越大,很多不大的公司都需要处理相当多的数据,这些小公司没有那么多的机器怎么办?
云计算来解决。很多的小公司都会在自己的云上安装大数据,干脆云平台,将其部署到PaaS,将其作为一个通用的应用。现在的公有云上,基本上都有大数据的解决方案了。如此一来,小公司不需要采购一千台机器,只要在公有云上一点击,千台机器出来了,而且上面已经部署好了,大数据平台,只要把数据放进去就行了。大数据和云计算两者完美的结合在了一起。
Saas:软件即服务,比如说人工智能程序。为什么智能程序是软件即服务呢?而不是像大数据解决方案那样作为PaaS呢,因为后者是一个集群,涉及到了PaaS中,而人工智能程序是程序,而且这个程序是大量的数据训练出来的,小公司并没有那么大的数据训练,如果用户单独安装一套,结果往往很差。云计算厂商往往积累了大量的数据,于是云计算厂商就在里面安装一套,暴露一个服务的接口。 当一个大数据公司积累了大量数据,会使用一些人工智能的算法提供一些服务;一个人工智能公司,也不可能没有大数据平台支撑。