SQL Server的聚焦过滤索引的详细信息
SQL Server的聚焦过滤索引的详细信息
前言
这一节我们还是继续讲讲索引知识,前面我们聚集索引、非聚集索引以及覆盖索引等,在这其中还有一个过滤索引,通过索引过滤我们也能提高查询性能,简短的内容,深入的理解。
过滤索引,在查询条件上创建非聚集索引(1)
过滤索引是SQL 2008的新特性,被应用在表中的部分行,所以利用过滤索引能够提高查询,相对于全表扫描它能减少索引维护和索引存储的代价。当我们在索引上应用WHERE条件时就是过滤索引。也就是满足如下格式:
CREATE NONCLUSTERED INDEX <index name> ON <table> (<columns>) WHERE <criteria>; GO
下面我们来看一个简单的查询
USE AdventureWorks2012 GO SELECT SalesOrderDetailID, UnitPrice FROM Sales.SalesOrderDetail WHERE UnitPrice > 2000 GO
上述列中未建立任何索引,当然除了SalesOrderDetailID默认创建的聚集索引,这种情况下我们能够猜想到其执行的查询计划必然是主键创建的聚集索引扫描,如下

上述我们已经说过此时未在查询条件上创建索引,所以此时必然走的是主键创建的聚集索引,接下来我们首先在UnitPrice列上创建非聚集索引来提高查询性能,
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_UnitPrice ON Sales.SalesOrderDetail(UnitPrice)
此时我们再来比较二者查询开销
USE AdventureWorks2012 GO DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS SELECT SalesOrderDetailID, UnitPrice FROM AdventureWorks2012.Sales.SalesOrderDetail WITH(INDEX([PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID])) WHERE UnitPrice > 2000 GO SELECT SalesOrderDetailID, UnitPrice FROM Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_UnitPrice])) WHERE UnitPrice > 2000
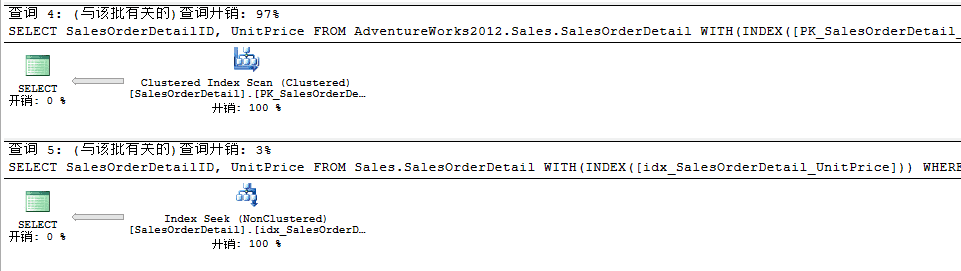
此时在查询条件上建立了非聚集索引之后,查询开销提升的非常明显,提升达到了90%以上,因为非聚集索引也会引用了主键创建的聚集索引,所以这个时候不会导致Bookmark Lookup或者Key Lookup查找。接下来我们我们再添加一个带有条件的非聚集索引即过滤索引
CREATE NONCLUSTERED INDEX idxwhere_SalesOrderDetail_UnitPrice ON Sales.SalesOrderDetail(UnitPrice) WHERE UnitPrice > 1000
此时我们再来看看创建了过滤索引之后和之前非聚集索引性能开销差异:
USE AdventureWorks2012 GO DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS SELECT SalesOrderDetailID, UnitPrice FROM AdventureWorks2012.Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_UnitPrice])) WHERE UnitPrice > 2000 SELECT SalesOrderDetailID, UnitPrice FROM Sales.SalesOrderDetail WITH(INDEX([idxwhere_SalesOrderDetail_UnitPrice])) WHERE UnitPrice > 2000

此时我们知道创建的非聚集过滤索引与传统创建的非聚集索引相比,我们的查询接近减少了一半。
唯一过滤索引
唯一过滤索引对于所有列必须唯一且不为空(只允许一个NULL存在)也是非常好的解决方案,所以此时在创建唯一过滤索引时需要将NULL值除外,比如如下:
CREATE UNIQUE NONCLUSTERED INDEX uq_fix_Customers_Email ON Customers(Email) WHERE Email IS NOT NULL GO
过滤索引结合INCLUDE
当我们再添加一个额外列时,使用默认主键创建的聚集索引时,此时会走聚集索引扫描,然后我们在查询条件上创建一个过滤索引,我们强制使用这个过滤索引时,此时由于添加额外列,会导致需要返回到基表中再去获取数据,所以也就造成了Key Lookup查找,如下:
USE AdventureWorks2012 GO SELECT SalesOrderDetailID, UnitPrice, UnitPriceDiscount FROM Sales.SalesOrderDetail WHERE UnitPrice > 2000 GO
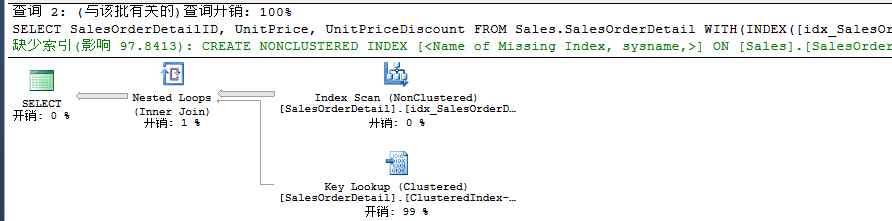
此时我们需要用INCLUDE来包含额外列。
CREATE NONCLUSTERED INDEX [idx_SalesOrderDetail_UnitPrice] ON Sales.SalesOrderDetail(UnitPrice) INCLUDE(UnitPriceDiscount)
我们再创建一个过滤索引同时包括额外列
CREATE NONCLUSTERED INDEX [idxwhere_SalesOrderDetail_UnitPrice] ON Sales.SalesOrderDetail(UnitPrice) INCLUDE(UnitPriceDiscount) WHERE UnitPrice > 2000
接下来再来执行比较添加过滤索引和未添加过滤索引同时都包括了额外列的性能查询差异。
SELECT SalesOrderDetailID, UnitPrice, UnitPriceDiscount FROM AdventureWorks2012.Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_UnitPrice])) WHERE UnitPrice > 2000 SELECT SalesOrderDetailID, UnitPrice, UnitPriceDiscount FROM Sales.SalesOrderDetail WITH(INDEX([idxwhere_SalesOrderDetail_UnitPrice])) WHERE UnitPrice > 2000
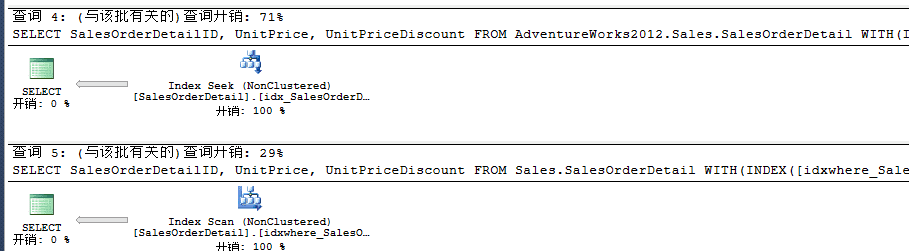
此时性能用INCLUDE来包含额外列性能也得到了一定的改善。
过滤索引,在主键上创建非聚集索引(2)
在第一个案列中,我们可以直接在查询列上创建非聚集索引,因为其类型是数字类型,要是查询条件是字符类型呢?首选现在我们先创建一个测试表
USE TSQL2012 GO CREATE TABLE dbo.TestData ( RowID integer IDENTITY NOT NULL, SomeValue VARCHAR(max) NOT NULL, StartDate date NOT NULL, CONSTRAINT PK_Data_RowID PRIMARY KEY CLUSTERED (RowID) );
添加10万条测试数据
USE TSQL2012 GO INSERT dbo.TestData WITH (TABLOCKX) (SomeValue, StartDate) SELECT CAST(N.n AS VARCHAR(max)) + 'JeffckyWang', DATEADD(DAY, (N.n - 1) % 31, '20140101') FROM dbo.Nums AS N WHERE N.n >= 1 AND N.n < 100001;
如果我们需要获取表TestData中SomeValue = 'JeffckyWang',此时我们想要在SomeValue上创建一个非聚集索引然后进行过滤,如下
USE TSQL2012 GO CREATE NONCLUSTERED INDEX idx_noncls_somevalue ON dbo.TestData(SomeValue) WHERE SomeValue = 'JeffckyWang'

更新
SQL Server对创建索引大小有限制,最大是900字节,上述直接写的VARCHAR(MAX),所以会出错,切记,切记。
此时我们在主键上创建非聚集索引,我们在主键RowID上创建一个过滤索引且SomeValue = 'JeffckyWang',然后返回数据,如下:
CREATE NONCLUSTERED INDEX idxwhere_noncls_somevalue ON dbo.TestData(RowID) WHERE SomeValue = 'JeffckyWang'
下面我们来对比建立过滤索引前后查询计划结果:
USE TSQL2012 GO SELECT RowID, SomeValue, StartDate FROM dbo.TestData WITH(INDEX([idx_pk_rowid])) WHERE SomeValue = 'JeffckyWang' SELECT RowID, SomeValue, StartDate FROM dbo.TestData WITH(INDEX([idxwhere_noncls_somevalue])) WHERE SomeValue = 'JeffckyWang'
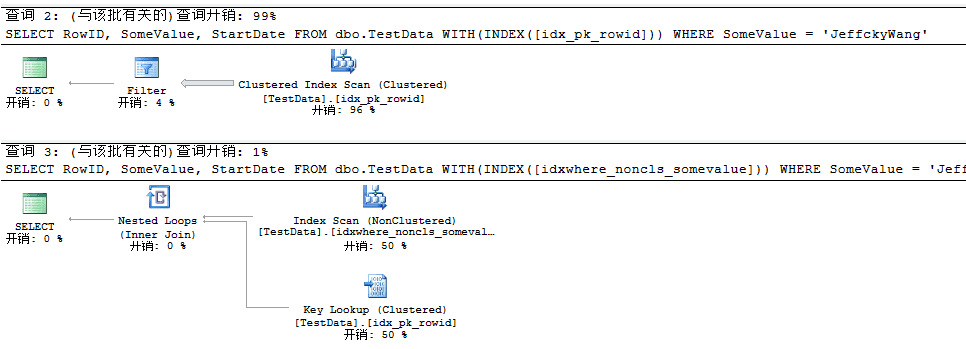
然后结合之前所学,移除Key Lookup,对创建的过滤索引进行INCLUDE。
CREATE NONCLUSTERED INDEX [idxwhere_noncls_somevalue] ON dbo.TestData(RowID) INCLUDE(SomeValue,StartDate) WHERE SomeValue = 'JeffckyWang'
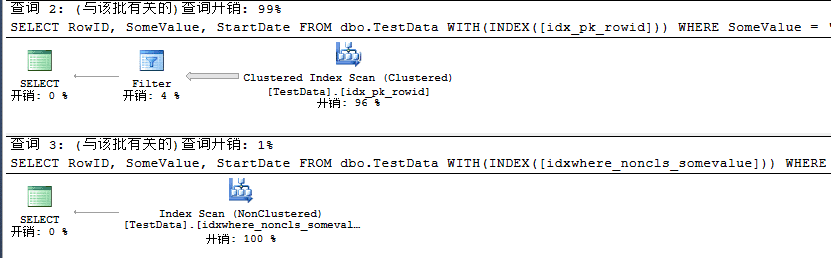
从这里看出,无论是对查询条件创建过滤索引还是对主键创建过滤索引,我们都可以通过结合之前所学来提高查询性能。
我们从开头就一直在讲创建过滤索引,那么创建过滤索引优点的条件到底是什么?
(1)只能通过非聚集索引进行创建。
(2)如果在视图上创建过滤索引,此视图必须是持久化视图。
(3)不能在全文索引上创建过滤索引。
过滤索引的优点
(1)减少索引维护成本:对于增、删、改等操作不需要代价没有那么昂贵,因为一个过滤索引的重建不需要耗时太多时间。
(2)减少存储成本:过滤索引的存储占用空间很校
(3)更精确的统计:通过在WHERE条件上创建过滤索引比全表统计结果更加精确。
(4)优化查询性能:通过查询计划可以看出其高效性。
讲到这里为止,一直陈述的是过滤索引的好处和优点,已经将其捧上天了,其实其缺点也是显而易见。
过滤索引缺点
最大的缺点则是查询条件的限制。其查询条件仅限于
<filter_predicate> ::= <conjunct> [ AND <conjunct> ] <conjunct> ::= <disjunct> | <comparison> <disjunct> ::= column_name IN (constant ,...n)
过滤条件仅限于AND、|、IN。比较条件仅限于 { IS | IS NOT | = | <> | != | > | >= | !> | < | <= | !< },所以如下利用LIKE不行
CREATE NONCLUSTERED INDEX [idxwhere_noncls_somevalue] ON dbo.TestData(RowID) INCLUDE(SomeValue,StartDate) WHERE SomeValue LIKE 'JeffckyWang%'

如下可以
USE AdventureWorks2012 GO CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_ModifiedDate ON Sales.SalesOrderDetail(ModifiedDate) WHERE ModifiedDate >= '2008-01-01' AND ModifiedDate <= '2008-01-07' GO
如下却不行
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_ModifiedDate ON Sales.SalesOrderDetail(ModifiedDate) WHERE ModifiedDate = GETDATE() GO

变量对过滤索引影响
上述我们创建过滤索引在查询条件上直接定义的字符串,如下:
CREATE NONCLUSTERED INDEX idxwhere_SalesOrderDetail_UnitPrice ON Sales.SalesOrderDetail(UnitPrice) WHERE UnitPrice > 1000
如果定义的是变量,利用变量来进行比较会如何呢?首先我们创建一个过滤索引
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_ProductID ON Sales.SalesOrderDetail (ProductID) WHERE ProductID = 870
利用变量来和查询条件比较,强制使用过滤索引(默认情况下走聚集索引)
USE AdventureWorks2012 GO DECLARE @ProductID INT SET @ProductID = 870 SELECT ProductID FROM Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_ProductID])) WHERE ProductID = @ProductID

查看查询执行计划结果却出错了,此时我们需要添加OPTION重新编译,如下:
USE AdventureWorks2012 GO DECLARE @ProductID INT SET @ProductID = 870 SELECT ProductID FROM Sales.SalesOrderDetail WHERE ProductID = @ProductID OPTION(RECOMPILE)

上述利用变量来查询最后通过OPTION重新编译在SQL Server 2012中测试好使,至于其他版本未知,参考资料【The Pains of Filtered Indexes】。
总结
本节我们学习了通过过滤索引来提高查询性能,同时也给出了其不同的场景以及其使用优点和明显的缺点。简短的内容,深入的理解,我们下节再会,good night。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,同时也希望多多支持路饭!