向Redis插入大量的数据的方法技巧
向Redis插入大量的数据的方法技巧
最近有个哥们在群里问,有一个日志,里面存的是IP地址(一行一个),如何将这些IP快速导入到Redis中。
我刚开始的建议是Shell+redis客户端。
今天,查看Redis官档,发现文档的首页部分(http://www.redis.io/documentation)有一个专门的主题是讲述“Redis Mass Insertion”的,才知道自己的建议很low。
官方给出的理由如下:
Using a normal Redis client to perform mass insertion is not a good idea for a few reasons: the naive approach of sending one command after the other is slow because you have to pay for the round trip time for every command. It is possible to use pipelining, but for mass insertion of many records you need to write new commands while you read replies at the same time to make sure you are inserting as fast as possible.
Only a small percentage of clients support non-blocking I/O, and not all the clients are able to parse the replies in an efficient way in order to maximize throughput. For all this reasons the preferred way to mass import data into Redis is to generate a text file containing the Redis protocol, in raw format, in order to call the commands needed to insert the required data.
大意是:
1> 每个redis客户端命令之间有往返时延。
2> 只要一部分客户端支持非阻塞I/O。
个人理解是,redis命令从执行到结果返回,有一定的时延,即便采用多个redis客户单并发插入,也很难提高吞吐量,因为,只有非阻塞I/O只能针对有限个连接操作。
那么如何高效的插入呢?
官方在2.6版本推出了一个新的功能-pipe mode,即将支持Redis协议的文本文件直接通过pipe导入到服务端。
说来拗口,具体实现步骤如下:
1. 新建一个文本文件,包含redis命令
SET Key0 Value0 SET Key1 Value1 ... SET KeyN ValueN
如果有了原始数据,其实构造这个文件并不难,譬如shell,python都可以
2. 将这些命令转化成Redis Protocol。
因为Redis管道功能支持的是Redis Protocol,而不是直接的Redis命令。
如何转化,可参考后面的脚本。
3. 利用管道插入
cat data.txt | redis-cli --pipe
Shell VS Redis pipe
下面通过测试来具体看看Shell批量导入和Redis pipe之间的效率。
测试思路:分别通过shell脚本和Redis pipe向数据库中插入10万相同数据,查看各自所花费的时间。
Shell
脚本如下:
#!/bin/bash for ((i=0;i<100000;i++)) do echo -en "helloworld" | redis-cli -x set name$i >>redis.log done
每次插入的值都是helloworld,但键不同,name0,name1...name99999。
Redis pipe
Redis pipe会稍微麻烦一点
1> 首先构造redis命令的文本文件
在这里,我选用了python
#!/usr/bin/python for i in range(100000): print 'set name'+str(i),'helloworld'
# python 1.py > redis_commands.txt
# head -2 redis_commands.txt
set name0 helloworld set name1 helloworld
2> 将这些命令转化成Redis Protocol
在这里,我利用了github上一个shell脚本,
#!/bin/bash
while read CMD; do
# each command begins with *{number arguments in command}\r\n
XS=($CMD); printf "*${#XS[@]}\r\n"
# for each argument, we append ${length}\r\n{argument}\r\n
for X in $CMD; do printf "\$${#X}\r\n$X\r\n"; done
done < redis_commands.txt
# sh 20.sh > redis_data.txt
# head -7 redis_data.txt
*3 $3 set $5 name0 $10 helloworld
至此,数据构造完毕。
测试结果
如下:
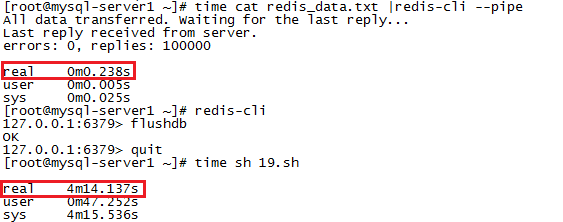
时间消耗完全不是一个量级的。
最后,来看看pipe的实现原理,
- redis-cli --pipe tries to send data as fast as possible to the server.
- At the same time it reads data when available, trying to parse it.
- Once there is no more data to read from stdin, it sends a special ECHO command with a random 20 bytes string: we are sure this is the latest command sent, and we are sure we can match the reply checking if we receive the same 20 bytes as a bulk reply.
- Once this special final command is sent, the code receiving replies starts to match replies with this 20 bytes. When the matching reply is reached it can exit with success.
即它会尽可能快的将数据发送到Redis服务端,并尽可能快的读取并解析数据文件中的内容,一旦数据文件中的内容读取完了,它会发送一个带有20个字节的字符串的echo命令,Redis服务端即根据此命令来确认数据已插入完毕。
总结:
后续有童鞋好奇,构造redis命令的时间和将命令转化为protocol的时间,这里一并贴下:
[root@mysql-server1 ~]# time python 1.py > redis_commands.txt real 0m0.110s user 0m0.070s sys 0m0.040s [root@mysql-server1 ~]# time sh 20.sh > redis_data.txt real 0m7.112s user 0m5.861s sys 0m1.255s
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持路饭。