优化Mongodb性能的方法技巧
优化Mongodb性能的方法技巧
前言
如何能让软件拥有更高的性能?我想这是一个大部分开发者都思考过的问题。性能往往决定了一个软件的质量,如果你开发的是一个互联网产品,那么你的产品性能将更加受到考验,因为你面对的是广大的互联网用户,他们可不是那么有耐心的。严重点说,页面的加载速度每增加一秒也许都会使你失去一部分用户,也就是说,加载速度和用户量是成反比的。那么用户能够接受的加载速度到底是多少呢?
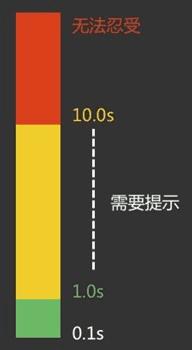
如图,如果页面加载时间超过10s那么用户就会离开,如果1s–10s的话就需要有提示,但如果我们的页面没有提示的话需要多快的加载速度呢?是的,1s 。
当然,这是站在一个产品经理的角度来说的,但如果站在一个技术人员的角度来说呢?加载速度和用户量就是成正比的,你的用户数量越多需要处理的数据当然也就越多,加载速度当然也就越慢。这是一件很有趣的事,所以如果你的产品如果是一件激动人心的产品,那么作为技术人员你需要做的事就是让软件的性能和用户的数量同时增长,甚至性能增长要快于用户量的增长。
Mongodb性能优化
数据库性能对软件整体性能有着至关重要的影响,对于Mongodb数据库常用的性能优化方法主要有:
1、范式化与反范式化;
2、填充因子的使用;
3、索引的使用;
一. 范式化与反范式化
范式是为了消除重复数据减少冗余数据,从而让数据库内的数据更好的组织,让磁盘空间得到更有效利用的一种标准化标准,满足高等级的范式的先决条件是满足低等级范式。在数据库设计阶段,明确集合的用途是对mongodb数据库性能调优非常重要的一步。根据集合中数据最常用的操作,对于频繁更新和频繁查询的集合,我们最需要关注的重点是他们的范式化程度。
1.1 范式化
1.1.1 范式化的优点:
1、范式化的数据库更新起来更加快;
2、范式化之后,只有很少的重复数据,只需要修改更少的数据;
3、范式化的表更小,可以在内存中执行;
4、很少的冗余数据,在查询的时候需要更少的distinct或者group by语句。
1.1.2 范式化的缺点:
1、范式化的表,在查询的时候经常需要很多的关联,因为单独一个表内不存在冗余和重复数据。这导致,稍微复杂一些的查询语句在查询范式的schema上都可能需要较多次的关联。这会增加让查询的代价,也可能使一些索引策略无效。因为范式化将列存放在不同的表中,而这些列在一个表中本可以属于同一个索引。
1.1.3 范式化设计的例子:
以存储一篇图书及其作者为例,作者的信息包括作者的姓名,年龄,国籍。使用范式化的设计如下:
“`
{
"_id" : ObjectId("5124b5d86041c7dca81917"),
"title" : "如何使用MongoDB",
"author" : [
ObjectId("144b5d83041c7dca84416"),
ObjectId("144b5d83041c7dca84418"),
ObjectId("144b5d83041c7dca84420"),
]
}
将作者(comment) 的id数组作为一个字段添加到了图书中去。这样的设计方式是在非关系型数据库中常用的。在MongoDB中我们将与主键没有直接关系的作者详细信息单独提取到另一个集合,用存储主键的方式进行关联查询。当我们要查询文章和作者时需要先查询到所需的文章,再从文章作者中获取作者id,最后获得的完整的文章及其作者详细信息。
在这种情况下查询性能显然是不理想的,因为需要进行较多的关联查询。但当某位作者的信息需要修改时,范式化的维护优势就凸显出来了,我们无需考虑此作者关联的图书,直接进行修改此作者的字段即可。
1.2. 反范式化
1.2.1 反范式化的优点:
1. 可以避免关联,因为所有的数据几乎都可以在一张表上显示;
2. 可以设计有效的索引;
1.2.2 反范式化的缺点:
1. 表格内的冗余较多,删除数据时候会造成表有些有用的信息丢失。
1.2.3 反范式化设计的例子:
以存储一篇图书及其作者为例,作者的信息包括作者的姓名,年龄,国籍。使用反范式化的设计如下:
{
"_id" : ObjectId("5124b5d86041c7dca81917"),
"title" : "如何使用MongoDB",
"author" : [
{
"name" : "丁磊"
"age" : 40,
"nationality" : "china",
},
{
"name" : "马云"
"age" : 49,
"nationality" : "china",
},
{
"name" : "张召忠"
"age" : 59,
"nationality" : "china",
},
]
}
在这个示例中我们将作者的字段完全嵌入到了图书中去,在查询的时候直接查询图书即可获得所对应作者的全部信息,但因一个作者可能有多本著作,当修改某位作者的信息时,我们需要遍历所有图书以找到该作者,将其修改。
1.3 范式化与反范式化混用
为了兼顾范式化与反范式化的优缺点,通常较常采用范式化与反范式化混合使用的方法,混合范式化与反范式化的设计如下:
“`
{
"_id" : ObjectId("5124b5d86041c7dca81917"),
"title" : "如何使用MongoDB",
"author" : [
{
"_id" : ObjectId("144b5d83041c7dca84416"),
"name" : "丁磊"
},
{
"_id" : ObjectId("144b5d83041c7dca84418"),
"name" : "马云"
},
{
"_id" : ObjectId("144b5d83041c7dca84420"),
"name" : "张召忠"
},
]
}
这次我们将作者字段中的最常用的一部分提取出来。当我们只需要获得图书和作者名时,无需再次进入作者集合进行查询,仅在图书集合查询即可获得。
这种方式是一种相对折中的方式,既保证了查询效率,也保证的更新效率。但这样的方式显然要比前两种较难以掌握,难点在于需要与实际业务进行结合来寻找合适的提取字段。如同示例3所述,名字显然不是一个经常修改的字段,这样的字段如果提取出来是没问题的,但如果提取出来的字段是一个经常修改的字段(比如age)的话,我们依旧在更新这个字段时需要大范围的寻找并依此进行更新。
在上面三个示例中,第一个示例的更新效率是最高的,但查询效率是最低的,而第二个示例的查询效率最高,但更新效率最低。所以在实际的工作中我们需要根据自己实际的需要来设计表中的字段,以获得最高的效率。
2.理解填充因子
何为填充因子?
填充因子(padding factor)是MongoDB为文档的扩展而预留的增长空间,因为MongoDB的文档是以顺序表的方式存储的,每个文档之间会非常紧凑,如图所示。
(注:图片出处:《MongoDB The Definitive Guide》)

1.元素之间没有多余的可增长空间。

2.当我们对顺序表中某个元素的大小进行增长的时候,就会导致原来分配的空间不足,只能要求其向后移动。

3.当修改元素移动后,后续插入的文档都会提供一定的填充因子,以便于文档频繁的修改,如果没有不再有文档因增大而移动的话,后续插入的文档的填充因子会依此减校
填充因子的理解之所以重要,是因为文档的移动非常消耗性能,频繁的移动会大大增加系统的负担,在实际开发中最有可能会让文档体积变大的因素是数组,所以如果我们的文档会频繁修改并增大空间的话,则一定要充分考虑填充因子。
那么如果我们的文档是个常常会扩展的话,应该如何提高性能?
两种方案
1.增加初始分配空间。在集合的属性中包含一个 usePowerOf2Sizes 属性,当这个选项为true时,系统会将后续插入的文档,初始空间都分配为2的N次方。这种分配机制适用于一个数据会频繁变更的集合使用,他会给每个文档留有更大的空间,但因此空间的分配不会像原来那样高效,如果你的集合在更新时不会频繁的出现移动现象,这种分配方式会导致写入速度相对变慢。
2.我们可以利用数据强行将初始分配空间扩大。
db.book.insert({
"name" : "MongoDB",
"publishing" : "清华大学出版社",
"author" : "john"
"tags" : []
"stuff" : "ggggggggggggggggggggggggggggggggggggg
ggggggggggggggggggggggggggggggggggggg
ggggggggggggggggggggggggggggggggggggg"
})
是的,这样看起来可能不太优雅…但有时却很有效!当我们对这个文档进行增长式修改时,只要将stuff字段删掉即可。当然,这个stuff字段随便你怎么起名,包括里边的填充字符当然也是可以随意添加的。
三. 索引的使用
索引对于一个数据库的影响相信大家一定了解,如果一个查询命令进入到数据库中后,查询优化器没有找到合适的索引,那么数据库会进行全集合扫描(在RDBMS中也叫全表扫描),全集合查询对于性能的影响是灾难性的。没有索引的查询就如同在词典那毫无规律的海量词汇中获得某个你想要的词汇,但这个词典是没有目录的,只能通过逐页来查找。这样的查找可能会让你耗费几个小时的时间,但如果要求你查询词汇的频率如同用户访问的频率一样的话。。。嘿嘿,我相信你一定会大喊“老子不干了1。显然计算机不会这样喊,它一直是一个勤勤恳恳的员工,不论多么苛刻的请求他都会完成。所以请通过索引善待你的计算机。但使用索引有两点需要注意:1. 索引越少越好;2. 索引颗粒越少越好。
3.1 索引越少越好
索引可以极大地提高查询性能,那么索引是不是越多越好?答案是否定的,并且索引并非越多越好,而是越少越好。每当你建立一个索引时,系统会为你添加一个索引表,用于索引指定的列,然而当你对已建立索引的列进行插入或修改时,数据库则需要对原来的索引表进行重新排序,重新排序的过程非常消耗性能,但应对少量的索引压力并不是很大,但如果索引的数量较多的话对于性能的影响可想而知。所以在创建索引时需要谨慎建立索引,要把每个索引的功能都要发挥到极致,也就是说在可以满足索引需求的情况下,索引的数量越少越好。
隐式索引
//建立复合索引
db.test.ensureIndex({"age": 1,"no": 1,"name": 1 })
我们在查询时可以迅速的将age,no字段进行排序,隐式索引指的是如果我们想要排序的字段包含在已建立的复合索引中则无需重复建立索引。
db.test.find().sort("age": 1,"no": 1)
db.test.find().sort("age": 1)
如以上两个排序查询,均可使用上面的复合索引,而不需要重新建立索引。
翻转索引
//建立复合索引
db.test.ensureIndex({"age": 1})
翻转索引很好理解,就是我们在排序查询时无需考虑索引列的方向,例如这个例子中我们在查询时可以将排序条件写为”{‘age': 0}”,依旧不会影响性能。
3.1 索引颗粒越少越好
什么叫颗粒越小越好?在索引列中每个数据的重复数量称为颗粒,也叫作索引的基数。如果数据的颗粒过大,索引就无法发挥该有的性能。例如,我们拥有一个"age"列索引,如果在"age"列中,20岁占了50%,如果现在要查询一个20岁,名叫"Tom"的人,我们则需要在表的50%的数据中查询,索引的作用大大降低。所以,我们在建立索引时要尽量将数据颗粒小的列放在索引左侧,以保证索引发挥最大的作用。
四. 总结
以上就是这篇文章的全部内容了,希望这篇文章的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流。