XSLT简介内容分析
XSLT简介内容分析
1.XSLT的概念
我们首先来澄清一个概念,大家可能听说过XSL(eXtensible Stylesheet Language),XSL和我们这里说的XSLT从狭义上理解是一样的,而按照W3C的标准,XSLT的说法更严格些,因此我们在文章中统一使用XSLT的称法。它们之间具体的关系我们会在下面讲述。
1.1 什么是XSLT
XSLT的英文标准名称为eXtensible Stylesheet Language Transformation。根据W3C的规范说明书(http://www.w3.org/TR/xslt),最早设计XSLT的用意是帮助XML文档(document)转换为其它文档。但是随着发展,XSLT已不仅仅用于将XML转换为HTML或其它文本格式,更全面的定义应该是:
XSLT是一种用来转换XML文档结构的语言。
1.2 为什么要用XSLT
我们已经知道,XML是一种电脑程序间交换原始数据的简单而标准的方法。它的成功并不在于它容易被人们书写和阅读,更重要的是,它从根本上解决了应用系统间的信息交换。因为XML满足了两个基本的需求:
(1).将数据和表达形式分离。就象天气预报的信息可以显示在不同的设备上,电视,手机或者其它。
(2).在不同的应用之间传输数据。电子商务数据交换的与日俱增使得这种需求越来越紧迫。
为了使数据便于人们的阅读理解,我们需要将信息显示出来或者打印出来,例如将数据变成一个HTML文件,一个PDF文件,甚至是一段声音;同样,为了使数据适合不同的应用程序,我们必须有能够将一种数据格式转换为另一种数据格式,比如需求格式可能是一个文本文件,一个SQL语句,一个HTTP信息,一定顺序的数据调用等。而XSLT就是我们用来实现这种转换功能的语言。将XML转换为HTML,是目前XSLT最主要的功能。
1.3 XSLT的历史
想很多其他XML家族成员一样,XSLT是由W3C起草和制定的。它的主要发展历程如下:
.1995年由James Clark提议;
.1997年8月正式提案为XSL;
.1998年5月由Norman Walsh完成需求概要;
.1998年8月18日XSL草案发布;
.1999年11月16日正式发布XSL 1.0推荐版本。
目前,XSLT仍然在快速的发展中,XSLT1.1的草案已经可以在W3C网站(http://www.w3.org/TR/xslt11)上看到。
1.4 什么是XPath
XPath是XSLT的重要组成部分,我们将在第四章讲解它的详细语法。那么XPath是什么呢?我们首先来了解一下XSL系列的"家族"关系。如下图:
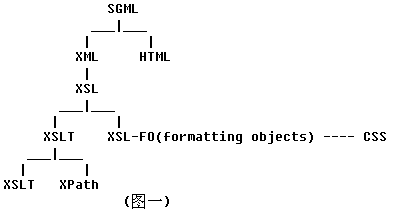
XSL在转换XML文档时分为明显的两个过程,第一转换文档结构;其次将文档格式化输出。这两步可以分离开来并单独处理,因此XSL在发展过程中逐渐分裂为XSLT(结构转换)和XSL-FO(formatting objects)(格式化输出)两种分支语言,其中XSL-FO的作用就类似CSS在HTML中的作用。而我们这里重点讨论的是第一步的转换过程,也就是XSLT。
另外,在学习XML时我们已经知道XML是一个完整的树结构文档。在转换XML文档时可能需要处理其中的一部分(节点)数据,那么如何查找和定位XML文档中的信息呢,XPath就是一种专门用来在XML文档中查找信息的语言。XPath隶属XSLT,因此我们通常会将XSLT语法和XPath语法混在一起说。
用一种比较好理解的解释:如果将XML文档看作一个数据库,XPath就是SQL查询语言;如果将XML文档看成DOS目录结构,XPath就是cd,dir等目录操作命令的集合。
1.5 XSLT和CSS的比较
CSS同样可以格式化XML文档,那么有了CSS为什么还需要XSLT呢?因为CSS虽然能够很好的控制输出的样式,比如色彩,字体,大小等,但是它有严重的局限性,就是:
(1) CSS不能重新排序文档中的元素;
(2) CSS不能判断和控制哪个元素被显示,哪个不被显示;
(3) CSS不能统计计算元素中的数据;
换句话说,CSS只适合用于输出比较固定的最终文档。CSS的优点是简洁,消耗系统资源少;而XSLT虽然功能强大,但因为要重新索引XML结构树,所以消耗内存比较多。
因此,我们常常将它们结合起来使用,比如在服务器端用XSLT处理文档,在客户端用CSS来控制显示。可以减少响应时间。
1.6 XSLT和IE5
在XSLT草案发布不久,微软就在IE4中提供了支持XSL功能的预览版本,到IE5.0发布时,正式全面支持XSLT,可是由于IE5发布的比XSLT1.0标准时间早,因此在IE5.0中支持的XSTL功能和XSLT 1.0略有不同。(呵呵~~XML推行的主要原因之一就是解决HTML过分依赖浏览器的问题,现在微软又想标新立异?)。好在微软的IE5.5中执行的标准已经和W3C的XSLT1.0基本相近。但令人头疼的是IE5.0已经发行了几百万套,您使用的XSLT很可能不能被客户的浏览器正确执行。目前XSLT 1.1仍在发展中,W3C及有关组织也在和微软协商争取获得统一。
2 用XPath精确定位节点元素
在利用XSL进行转换的过程中,匹配的概念非常重要。在模板声明语句 xsl:template match = ""和模板应用语句xsl:apply-templates select = "" 中,用引号括起来的部分必须能够精确地定位节点。具体的定位方法则在XPath中给出。
之所以要在XSL中引入XPath的概念,目的就是为了在匹配XML文档结构树时能够准确地找到某一个节点元素。可以把XPath比作文件管理路径:通过文件管理路径,可以按照一定的规则查找到所需要的文件;同样,依据XPath所制定的规则,也可以很方便地找到XML结构文档树中的任何一个节点,显然这对XSLT来说是一个最最基本的功能。
XPath数据类型
XPath可分为四种数据类型:
节点集(node-set)
节点集是通过路径匹配返回的符合条件的一组节点的集合。其它类型的数据不能转换为节点集。
布尔值(boolean)
由函数或布尔表达式返回的条件匹配值,与一般语言中的布尔值相同,有true和 false两个值。布尔值可以和数值类型、字符串类型相互转换。
字符串(string)
字符串即包含一系列字符的集合,XPath中提供了一系列的字符串函数。字符串可与数值类型、布尔值类型的数据相互转换。
数值(number)
在XPath中数值为浮点数,可以是双精度64位浮点数。另外包括一些数值的特殊描述,如非数值NaN(Not-a-Number)、正无穷大infinity、负无穷大-infinity、正负0等等。number的整数值可以通过函数取得,另外,数值也可以和布尔类型、字符串类型相互转换。
其中后三种数据类型与其它编程语言中相应的数据类型差不多,只是第一种数据类型是XML文档树的特有产物。
XPath节点类型
另外,由于XPath包含的是对文档结构树的一系列操作,因此搞清楚XPath节点类型也是很必要的。回忆一下第二章中讲到的XML文档的逻辑结构,一个XML文件可以包含元素、CDATA、注释、处理指令等逻辑要素,其中元素还可以包含属性,并可以利用属性来定义命名空间。相应地,在XPath中,将节点划分为七种节点类型:
根节点(Root Node)
根节点是一棵树的最上层,根节点是唯一的。树上其它所有元素节点都是它的子节点或后代节点。对根节点的处理机制与其它节点相同。在XSLT中对树的匹配总是先从根节点开始。
元素节点(Element Nodes)
元素节点对应于文档中的每一个元素,一个元素节点的子节点可以是元素节点、注释节点、处理指令节点和文本节点。可以为元素节点定义一个唯一的标识id。元素节点都可以有扩展名,它是由两部分组成的:一部分是命名空间URI,另一部分是本地的命名。
文本节点(Text Nodes)
文本节点包含了一组字符数据,即CDATA中包含的字符。任何一个文本节点都不会有紧邻的兄弟文本节点,而且文本节点没有扩展名。
属性节点(Attribute Nodes)
每一个元素节点有一个相关联的属性节点集合,元素是每个属性节点的父节点,但属性节点却不是其父元素的子节点。这就是说,通过查找元素的子节点可以匹配出元素的属性节点,但反过来不成立,只是单向的。再有,元素的属性节点没有共享性,也就是说不同的元素节点不共有同一个属性节点。
对缺省属性的处理等同于定义了的属性。如果一个属性是在DTD声明的,但声明为 #IMPLIED,而该属性没有在元素中定义,则该元素的属性节点集中不包含该属性。
此外,与属性相对应的属性节点都没有命名空间的声明。命名空间属性对应着另一种类型的节点。
命名空间节点(Namespace Nodes)
每一个元素节点都有一个相关的命名空间节点集。在XML文档中,命名空间是通过保留属性声明的,因此,在XPath中,该类节点与属性节点极为相似,它们与父元素之间的关系是单向的,并且不具有共享性。
处理指令节点(Processing Instruction Nodes)
处理指令节点对应于XML文档中的每一条处理指令。它也有扩展名,扩展名的本地命名指向处理对象,而命名空间部分为空。
注释节点(Comment Nodes)
注释节点对应于文档中的注释。
一个XML文档树
我们来构造一棵XML文档树,作为后面举例的依托:
<A id="a1">
<B id="b1">
<C id="c1">
<B name="b"/>
<D id="d1"/>
<E id="e1"/>
<E id="e2"/>
</C>
</B>
<B id="b2"/>
<C id="c2">
<B/>
<D id="d2"/>
<F/>
</C>
<E/>
</A>
以下将要介绍一些XPath中节点匹配的基本方法。
路径匹配
路径匹配与文件路径的表示相仿,比较好理解。有以下几个符号:
(1)用“/”指示节点路径
如“/A/C/D” 表示节点"A"的子节点"C"的子节点"D",即id值为d2的D节点, “/”表示根节点。
(2)用“//” 表示所有路径以"//"后指定的子路径结尾的元素
如“//E” 表示所有E元素,结果是所有三个E元素,如“//C/E”表示所有父节点为C的E元素,结果是id值为e1和e2的两个E元素 。
(3)用“*” 表示路径的通配符
如“/A/B/C/*”表示 A元素→B元素→C元素下的所有子元素,即name值为b的B元素、 id值为d1的D元素和id值为e1和e2的两个E元素
“/*/*/D”表示上面有两级节点的D元素,匹配结果是id值为d2的D元素 ,如“//*”表示所有的元素。
位置匹配
对于每一个元素,它的各个子元素是有序的。
如:/A/B/C[1]表示A元素→B元素→C元素的第一个子元素,得到name值为b的B元素
/A/B/C[last()]表示A元素→B元素→C元素的最后一个子元素,得到id值为e2的E元素
/A/B/C[position()>1]表示A元素→B元素→C元素之下的位置号大于1的元素,得到id值为d1的D元素和两个具有id值的E元素
属性及属性值
在XPath中可以利用属性及属性值来匹配元素,要注意的是,元素的属性名前要有"@"前缀。例如:
//B[@id]表示所有具有属性id的B元素,结果为id值为b1和b2的两个B元素
//B[@*]表示所有具有属性的B元素,结果为两个具有id属性的B元素和一个具有name属性B元素
//B[not(@*)]表示所有不具有属性的B元素,结果为A元素→C元素下的B元素
//B[@id="b1"] id值为b1的B元素,结果为A元素下的B元素
亲属关系匹配
XML文档可归结为树型结构,因此任何一个节点都不是孤立的。通常我们把节点之间的归属关系归结为一种亲属关系,如父亲、孩子、祖先、后代、兄弟等等。在对元素进行匹配时,同样可以用到这些概念。例如:
//E/parent::* 表示所有E节点的父节点元素,结果为id值为a1的A元素和id值为c1的C元素
//F/ancestor::* 表示所有F元素的祖先节点元素,结果为id值为a1的A元素和id值为c2的C元素
/A/child::* 表示A的子元素,结果为id值为b1、b2的B元素,id值为c2的C元素,以及没有任何属性的E元素
/A/descendant::* 表示A的所有后代元素,结果为除A元素以外的所有其它元素
//F/self::* 表示所有F的自身元素,结果为F元素本身
//F/ancestor-or-self::* 表示所有F元素及它的祖先节点元素,结果为F元素、F元素的父节点C元素和A元素
/A/C/descendant-or-self::* 表示所有A元素→C元素及它们的后代元素,结果为id值为c2的C元素、该元素的子元素B、D、F元素
/A/C/following-sibling::* 表示A元素→C元素的紧邻的后序所有兄弟节点元素,结果为没有任何属性的E元素
/A/C/preceding-sibling::* 表示A元素→C元素的紧邻的前面所有兄弟节点元素,结果为id值为b1和b2的两个B元素
/A/B/C/following::* 表示A元素→B元素→C元素的后序的所有元素,结果为id 为b2的B元素、无属性的C元素、无属性的B元素、id为d2的D元素、无属性的F元素、/无属性的E元素。
/A/C/preceding::* 表示A元素→C元素的前面的所有元素,结果为id为b2的B元素、id为e2的E元素、id为e1的E元素、id为d1的D元素、name为 b的B元素、id为c1的C元素、id为b1的B元素
条件匹配
条件匹配就是利用一些函数的运算结果的布尔值来匹配符合条件的节点。常用于条件匹配的函数有四大类:节点函数、字符串函数、数值函数、布尔函数。例如last()、position()等等,这里我们就不再赘述。
以上这些匹配方法中,用得最多的还要数路径匹配。在上一章样式表的例子中,无论是在语句<xsl:template match="学生花名册">中,还是在语句 <xsl:value-of select="名字"/>中,都是依靠给出相对于当前路径的子路径来定位节点的。
3. XQuery ,可以参考w3cChina "XQuery 1.0:XML查询语言 工作草案-1".
3.1 什么是XQuery(from:http://www.woodpecker.org.cn:9081/doc/XML/tutor/x-xquery/x-xquery/index3.html)
XML Query(XQuery)是在 XML 数据中搜索特定信息的功能强大的新方法。与 XPath 2.0 的起源相同,XQuery 的某些方面 — 如传统的 XPath 表达式 — 看上去很熟悉,而其它方面(如 FLWR 和条件语句)则是全新的。为了帮助消除解释问题,XQuery 工作组创建了“XML Query Use Cases”文档(请参阅参考资料,它提供了样本查询及其预期的结果。本教程中的示例都基于为该文档创建的样本数据。
XQuery 是 XML 规范和 W3C 建议书之间相互关系的优秀示例。XQuery 工作组与 XSL 工作组还一起负责 XPath 2.0 工作草案,XPath 2.0 将包括许多为 XQuery 开发的功能。
除了对 XPath 的增强外,XQuery 还允许您通过嵌套类 SQL 的子句来创建复杂查询,以及通过将 XML 构造器直接包括在输出中来创建复杂结果。本章概述了 XQuery 的这些方面,然后将更详细地讨论每个方面。
3.2 XPath 2.0 增强
对 XPath 的增强通常分成四种类别:
序列:XPath 1.0 通常返回节点集,而 XPath 2.0 返回序列。如序列中讨论的那样,序列与节点集相似,但提供了更多的能力。节点集和序列之间最重要的差异之一是:与序列不同,节点集是无序的。每个 XPath 2.0 表达式都返回一个序列,即使它是只有一项的序列。
数据类型:XPath 1.0 理解四种数据类型:node-sets、strings、booleans 和 numbers。XPath 2.0 不仅包含对 XML Schema 内置数据类型的支持,而且还包含对用户定义的数据类型的支持。
增强的函数集:XPath 2.0 包括用于操作数据的函数,就象 1.0 一样。它还包括相当健壮的序列比较支持,如检查节点是否等于特定的深度或选择两个序列的交集或并集的能力。
多个数据源:XPath 2.0 包含显式地为表达式设置数据源的能力,这使将多个数据源中的数据合并到单个查询成为可能。
3.3 FLWR 语句
FLWR 是 FOR-LET-WHERE-RETURN 的缩写,它描述了典型 XQuery 的结构。在 FLWR 语句中,数据被绑定到变量,然后,后续步骤使用该变量。例如,使用下面的语句:
for $book in
document("http://www.bn.com/bib.xml")//book
let $title := $book/title
where $book/publisher = 'Addison-Wesley'
return
<bookInfo>
{ $title }
</bookInfo>
该语句返回原始文档中每个 book 元素的 bookInfo 元素,其中 book 元素的 publisher 子元素为 Addison-Wesley。每个 bookInfo 元素都有 title 子元素,如下所示:
<bookInfo>
<title>TCP/IP Illustrated</title>
</bookInfo>
<bookInfo>
<title>Advanced Programming in the Unix environment</title>
</bookInfo>
3.4 构造器
构造器是创建 XML 元素和属性、CDATA 节、注释,或处理 XQuery 表达式结果内部指令的方法。XQuery 建议书描述了两种构造器,它们允许直接创建元素,而不是由 XSLT template 元素间接创建。第一种是典型的构造器,它只是将结果嵌入到元素或其它构造中,如下面的表达式中说明的那样:<books>
{
for $book in input()/bib/book
return
<itemInfo>
{ $book/title }
{ $book/price }
</itemInfo>
}
</books>
第二种称为计算构造器,因为它允许创建名称由表达式结果决定的元素。3.5 序列 序列相对于节点集的主要优势之一在于序列是有序的。实际上,XPath 1.0 表达式可以根据文档次序挑选节点,而 XPath 2.0 了解序列本身的次序。例如,下面的语句输出任何操作的文本,这些操作发生在一个操作的第一个过程的第一个和第二个“缺口(incision)”之间。<critical_sequence>
{
let $proc := document("/XQuery/docs/SEQ/report1.xml")
//section[section.title="Procedure"][1]
for $n in $proc//node()
where $n follows ($proc//incision)[1]
and $n precedes ($proc//incision)[2]
return $n/text()
}
</critical_sequence>
序列不仅只确定节点出现的次序,而且在如何组合它们及它们是如何交互的方面也起到很重要的作用。
3.5 函数
XQuery 提供了定义函数的能力,这些函数随后可在其它表达式中使用。例如:define function summary(element employee* $emps)
returns element dept*
{
for $d in distinct-values($emps/deptno)
let $e := $emps[deptno = $d]
return
<dept>
{$d}
<headcount> {count($e)} </headcount>
<payroll> {sum($e/salary)} </payroll>
</dept>
}
summary(document("acme_corp.xml")//employee[location = "Denver"])
有了这种能力,不仅可以使用由 XPath 2.0 预先定义的函数,而且可以根据需要定义您自己的函数。3.6多个数据源 XQuery 的最主要优势之一是,它能够通过为特定的表达式显式地指定数据源来合并来自多个数据源的输入。例如,下面的查询:<result>
{
for $i in document("items.xml") //item_tuple
let $b := document("bids.xml") //bid_tuple[itemno= $i/itemno]
where contains($i/description, "Bicycle")
return
<item_tuple>
{ $i/itemno }
{ $i/description }
<high_bid>{ max(for $z in $b/bid return decimal($z)) }</high_bid>
</item_tuple>
sortby(itemno)
}
</result>
将文件 items.xml 中的信息与另一个文件 bids.xml 中的信息进行比较。结果包含来自两个文件的信息。
4. 关于xslt的W3C Recommendation,可以参考:http://www.w3.org/TR/xslt