数据挖掘算法分析
分类
分类是用于识别什么样的事务属于哪一类的方法,可用于分类的算法有决策树、bayes分类、神经网络、支持向量机等等。
决策树
例1
一个自行车厂商想要通过广告宣传来吸引顾客。他们从各地的超市获得超市会员的信息,计划将广告册和礼品投递给这些会员。
但是投递广告册是需要成本的,不可能投递给所有的超市会员。而这些会员中有的人会响应广告宣传,有的人就算得到广告册不会购买。
所以最好是将广告投递给那些对广告册感兴趣从而购买自行车的会员。分类模型的作用就是识别出什么样的会员可能购买自行车。
自行车厂商首先从所有会员中抽取了1000个会员,向这些会员投递广告册,然后记录这些收到广告册的会员是否购买了自行车。
数据如下:
|
事例列 |
会员编号 |
12496 |
14177 |
24381 |
25597 |
………… |
|
输入列 |
婚姻状况 |
Married |
Married |
Single |
Single |
|
|
性别 |
Female |
Male |
Male |
Male |
||
|
收入 |
40000 |
80000 |
70000 |
30000 |
||
|
孩子数 |
1 |
5 |
0 |
0 |
||
|
教育背景 |
Bachelors |
Partial College |
Bachelors |
Bachelors |
||
|
职业 |
Skilled Manual |
Professional |
Professional |
Clerical |
||
|
是否有房 |
Yes |
No |
Yes |
No |
||
|
汽车数 |
0 |
2 |
1 |
0 |
||
|
上班距离 |
0-1 Miles |
2-5 Miles |
5-10 Miles |
0-1 Miles |
||
|
区域 |
Europe |
Europe |
Pacific |
Europe |
||
|
年龄 |
42 |
60 |
41 |
36 |
||
|
预测列 |
是否购买自行车 |
No |
No |
Yes |
Yes |
在分类模型中,每个会员作为一个事例,居民的婚姻状况、性别、年龄等特征作为输入列,所需预测的分类是客户是否购买了自行车。
使用1000个会员事例训练模型后得到的决策树分类如下:
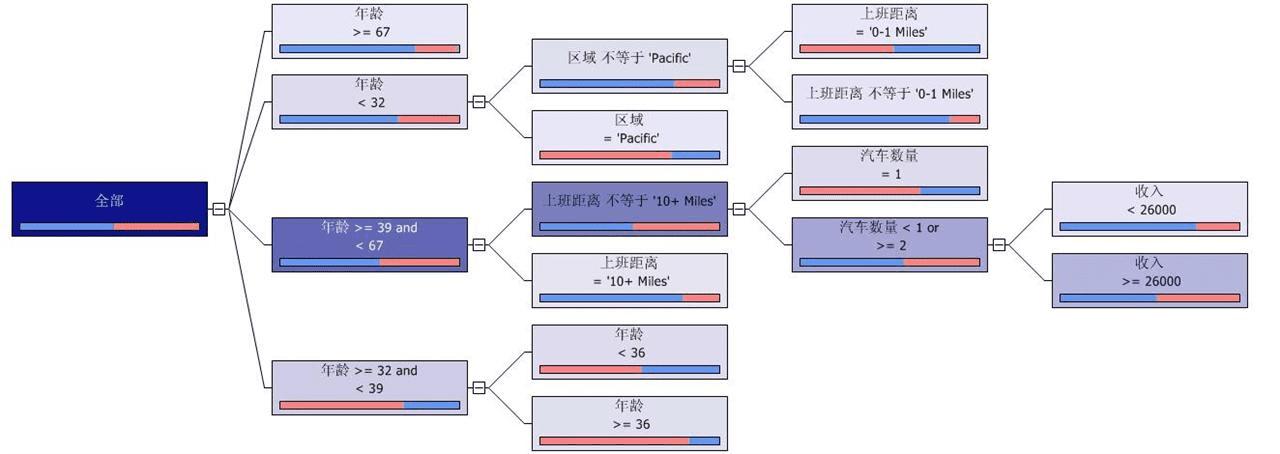
※图中矩形表示一个拆分节点,矩形中文字是拆分条件。
※矩形颜色深浅代表此节点包含事例的数量,颜色越深包含的事例越多,如全部节点包含所有的1000个事例,颜色最深。经过第一次基于年龄的拆分后,年龄大于67岁的包含36个事例,年龄小于32岁的133个事例,年龄在39和67岁之间的602个事例,年龄32和39岁之间的229个事例。所以第一次拆分后,年龄在39和67岁的节点颜色最深,年龄大于67岁的节点颜色最浅。
※节点中的条包含两种颜色,红色和蓝色,分别表示此节点中的事例购买和不购买自行车的比例。如节点“年龄>=67”节点中,包含36个事例,其中28个没有购买自行车,8个购买了自行车,所以蓝色的条比红色的要长。表示年龄大于67的会员有74.62%的概率不购买自行车,有23.01%的概率购买自行车。
在图中,可以找出几个有用的节点:
1. 年龄小于32岁,居住在太平洋地区的会员有72.75%的概率购买自行车;
2. 年龄在32和39岁之间的会员有68.42%的概率购买自行车;
3. 年龄在39和67岁之间,上班距离不大于10公里,只有1辆汽车的会员有66.08%的概率购买自行车;
4. 年龄小于32岁,不住在太平洋地区,上班距离在1公里范围内的会员有51.92%的概率购买自行车;
在得到了分类模型后,将其他的会员在分类模型中查找就可预测会员购买自行车的概率有多大。随后自行车厂商就可以有选择性的投递广告册。
|
数据挖掘的一般流程 第一步,建立模型,确定数据表中哪些列是要用于输入,哪些是用于预测,选择用何种算法。这时建立的模型内容是空的,在模型没有经过训练之前,计算机是无法知道如何分类数据的。 第二步,准备模型数据集,例子中的模型数据集就是1000个会员数据。通常的做法是将模型集分成训练集和检验集,比如从1000个会员数据中随机抽取700个作为训练集,剩下300个作为检验集。 第三步,用训练数据集填充模型,这个过程是对模型进行训练,模型训练后就有分类的内容了,像例子图中的树状结构那样,然后模型就可以对新加入的会员事例进行分类了。由于时效性,模型内容要经常更新,比如十年前会员的消费模式与现在有很大的差异,如果用十年前数据训练出来的模型来预测现在的会员是否会购买自行车是不合适的,所以要按时使用新的训练数据集来训练模型。 第四步,模型训练后,还无法确定模型的分类方法是否准确。可以用模型对300个会员的检验集进行查询,查询后,模型会预测出哪些会员会购买自行车,将预测的情况与真实的情况对比,评估模型预测是否准确。如果模型准确度能满足要求,就可以用于对新会员进行预测。 第五步,超市每天都会有新的会员加入,这些新加入的会员数据叫做预测集或得分集。使用模型对预测集进行预测,识别出哪些会员可能会购买自行车,然后向这些会员投递广告。
|
Na"ive Bayes
Na"ive Bayes是一种由统计学中Bayes法发展而来的分类方法。
例1
有A、B两个政党对四个议题进行投票,A政党有211个国会议员,B政党有223个国会议员。下表统计了政党对四个议题赞成或反对的票数。
|
|
国家安全法 |
个人财产保护法 |
遗产税 |
反分裂法 |
总计 |
||||
|
|
赞成 |
反对 |
赞成 |
反对 |
赞成 |
反对 |
赞成 |
反对 |
|
|
A政党 |
41 |
166 |
87 |
114 |
184 |
11 |
178 |
23 |
211 |
|
B政党 |
214 |
4 |
211 |
6 |
172 |
36 |
210 |
1 |
223 |
|
|
|
|
|
|
|
|
|
|
|
|
A政党 |
20% |
80% |
43% |
57% |
94% |
6% |
89% |
11% |
49% |
|
B政党 |
98% |
2% |
97% |
3% |
83% |
17% |
99.50% |
0.50% |
51% |
A政党的议员有20%概率赞成国家安全法,43%概率赞成个人财产保护法,94%概率赞成遗产税,89%概率赞成反分裂法。
B政党的议员有98%概率赞成国家安全法,97%概率赞成个人财产保护法,83%概率赞成遗产税,99.5%概率赞成反分裂法。
基于这样的数据,Na"ive Bayes能预测的是如果一个议员对国家安全法投了赞成票,对个人财产保护法投了反对票,对遗产税投了赞成票,对反分裂法投了赞成票。哪么,这个议员有多大的概率属于A政党,又有多少的概率属于B政党。
例2
一个产品在生产后经检验分成一等品、二等品、次品。生产这种产品有三种可用的配方,两种机器,两个班组的工人。下面是1000个产品的统计信息。
|
|
配方 |
机器 |
工人 |
总计 |
||||
|
|
配方1 |
配方2 |
配方3 |
机器1 |
机器2 |
班组1 |
班组2 |
|
|
一等品 |
47 |
110 |
121 |
23 |
255 |
130 |
148 |
278 |
|
二等品 |
299 |
103 |
165 |
392 |
175 |
327 |
240 |
567 |
|
次品 |
74 |
25 |
56 |
69 |
86 |
38 |
117 |
155 |
|
|
|
|
|
|
|
|
|
|
|
一等品 |
16.91% |
39.57% |
43.53% |
8.27% |
91.73% |
46.76% |
53.24% |
27.80% |
|
二等品 |
52.73% |
18.17% |
29.10% |
69.14% |
30.86% |
57.67% |
42.33% |
56.70% |
|
次品 |
47.74% |
16.13% |
36.13% |
44.52% |
55.48% |
24.52% |
75.48% |
15.50% |
使用Na"ive Bayes模型,每次在制定生产计划,确定生产产品所用的配方、机器及工人,便能预测生产中有多少的一等品、二等品和次品。
神经网络
神经网络是一种模拟生物上神经元的工作的机器学习方法。
下面是银行用来识别给申请信用卡的客户发放何种信用卡的神经网络。

图中每个椭圆型节点接受输入数据,将数据处理后输出。输入层节点接受客户信息的输入,然后将数据传递给隐藏层,隐藏层将数据传递给输出层,输出层输出客户属于哪类信用卡。这类似于人脑神经元受到刺激时,神经脉冲从一个神经元传递到另一个神经元。
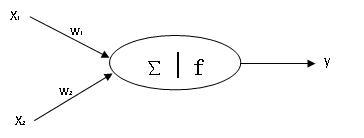
每个神经元节点内部包含有一个组合函数∑和激活函数f。X1, X2是其他神经元的输出值,对此神经元来说是输入值,组合函数将输入值组合后传递给激活函数。激活函数经过特定的计算后得到输出值y,y有被传递给其他神经元。
输入边上的w1和w2是输入权值,用于在组合函数中对每个输入值进行加权。训练模型时,客户事例输入,神经网络计算出客户的类别,计算值与真实值比较后,模型会修正每个输入边上的权值。在大量客户事例输入后,模型会不断调整,使之更吻合真实情况,就像是人脑通过在同一脉冲反复刺激下改变神经键连接强度来进行学习。
回归
分类算法是建立事例特征对应到分类的方法。分类必须是离散的,像信用卡的种类只有三种,如果是要通过客户收入、婚姻状况、职业等特征预测客户会使用信用卡消费多少金额时,分类算法就无能为力了,因为消费金额可能是大于0的任意值。这时只能使用回归算法。
例如,下表是工厂生产情况。
|
机器数量 |
工人数量 |
生产数量 |
|
12 |
60 |
400 |
|
7 |
78 |
389 |
|
11 |
81 |
674 |
|
…… |
||
使用线性回归后,得到了一个回归方程:生产数量=α+β·机器数量+γ·工人数量。代表每多一台机器就可以多生产β单位的产品,每多一个工人就可以多生产γ单位的产品。
除了简单的线性回归和逻辑回归两种,决策树可以建立自动回归树模型,神经网络也可以进行回归,实际上,逻辑回归就是去掉隐藏层的神经网络。
例如,服装销售公司要根据各地分销店面提交的计划预计实际销售量。
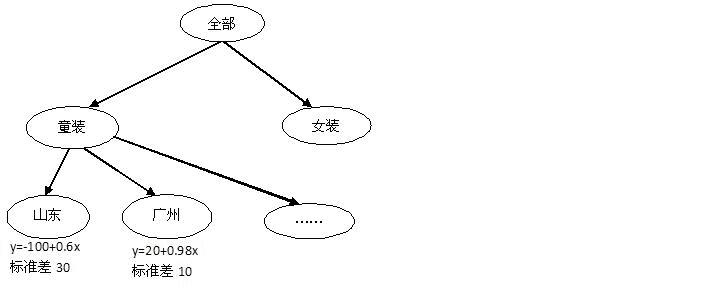
使用自动回归树得到上图的模型,假如山东销售店提交的计划童装数量是500套,预计销售量是-100+0.6×500=200套,按6Sigma原则,有99.97%的概率实际销售量可能是200±90套。广州提交计划童装300套,预计销售量是20+0.98×300=314±30套。广州的销售店制定的童装计划比山东的准确。
聚类
分类算法的目的是建立事例特征到类别的对应法则。但前提是类别是已存在的,如已知道动物可以分成哺乳类和非哺乳类,银行发行的信用卡有银卡、金卡、白金卡三种。
有时在分类不存在前,要将现有的事例分成几类。比如有同种材料要分类装入到各个仓库中,这种材料有尺寸、色泽、密度等上百个指标,如果不熟悉材料的特性很难找到一种方法将材料分装。
又例如,银行刚开始信用卡业务时,没有将客户分类,所有的客户都使用同一种信用卡。在客户积累到一定的数量后,为了方便管理和制定市场策略,需要将客户分类,让不同类别的客户使用不同的信用卡。但问题是,银行该把客户分成几个类别,谁该属于哪一类。
假定银行仅仅要参照客户的收入和使用信用卡销售金额两个指标对客户分类。通常情况下,仅仅是衡量这些指标的高低来分类,如规定收入小于4000,且消费小于2000的客户分成第一类;收入在4000至8000,消费在2000至4000的客户分成第二类;收入在8000至12000,消费在4000至6000的客户分成第三类;收入在12000以上,消费在6000以上分成第四类。下面的图展示了这种分类。
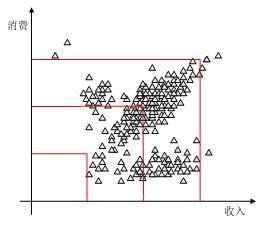
图中三角形的点代表客户,图中的红色线条是对客户的分类。可以看到这种不合理,第一类别没有包含任何事例,而第四类也只有少量事例,而第二和第三类分界处聚集着大量事例。
观测图像,发现大部分客户事例聚集在一起形成了三个簇,下图中用三个椭圆标出了这些簇。
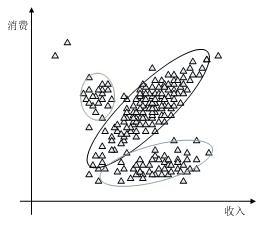
同在一个簇中的客户有着类似的消费行为,黑色簇中的客户消费额与收入成正比;蓝色簇中的客户不习惯使用信用卡消费,可以对这类客户发放一种低手续费的信用卡,鼓励他们使用信用卡消费;绿色簇中的客户消费额相对收入来说比较高,应该为这类客户设计一种低透支额度的信用卡。
聚类模型就是这种可以识别有着相似特征事例,把这些事例聚集在一起形成一个类别的算法。
聚类模型除了能将相似特征的事例归为一类外,还常用来发现异常点。
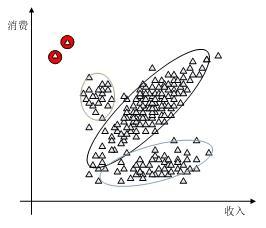
像上图中用红圈标出的点,这两个客户偏离了已有的簇,他们的消费行为异于一般人,消费远超出收入。意味他们有其他不公开的收入来源,这些客户是有问题的。
科学试验中,研究人员对异常点很感兴趣,通过研究不寻常的现象提出新的理论。
聚类的另一个用途是发现属性间隐含的关系。例如有30名学生考试成绩:
|
学号 |
美术 |
语文 |
物理 |
历史 |
英语 |
音乐 |
数学 |
化学 |
|
31001 |
74 |
50 |
89 |
61 |
53 |
65 |
96 |
87 |
|
31002 |
70 |
65 |
88 |
55 |
50 |
65 |
92 |
87 |
|
31003 |
65 |
50 |
86 |
54 |
63 |
73 |
91 |
96 |
|
…… |
||||||||
教师想知道学科之间是否有关联,如果学生某门学科成绩优秀,是否会在另一门学科上也有优势。
通过聚类后将30名学生分成了3个类:
|
变量 |
状态 |
总体(全部) |
分类 3 |
分类 2 |
分类 1 |
|
大小 |
|
30 |
10 |
10 |
10 |
|
语文 |
平均值 |
74 |
71.6 |
89.6 |
59.4 |
|
语文 |
偏差 |
13.39 |
4.38 |
3.95 |
5.46 |
|
英语 |
平均值 |
72 |
72.7 |
88.1 |
56.1 |
|
英语 |
偏差 |
14.27 |
4.4 |
6.9 |
4.46 |
|
音乐 |
平均值 |
78 |
89.1 |
74.4 |
71 |
|
音乐 |
偏差 |
9.71 |
7.31 |
4.12 |
5.27 |
|
物理 |
平均值 |
75 |
74 |
56.6 |
93.4 |
|
物理 |
偏差 |
15.96 |
4.42 |
4.84 |
4.95 |
|
数学 |
平均值 |
75 |
74.3 |
57.3 |
92.3 |
|
数学 |
偏差 |
15.16 |
4.4 |
3.97 |
4.95 |
|
美术 |
平均值 |
78 |
90.6 |
71.8 |
71.4 |
|
美术 |
偏差 |
10.43 |
5.38 |
4.71 |
5.66 |
|
历史 |
平均值 |
73 |
73.2 |
87.6 |
58.1 |
|
历史 |
偏差 |
13.23 |
5.85 |
4.43 |
5.13 |
|
化学 |
平均值 |
74 |
74.7 |
56.2 |
90.6 |
|
化学 |
偏差 |
15.09 |
3.06 |
5.39 |
6.02 |
分类1学生的共同特点是他们的物理、数学、化学平均分都比较高,但语文、历史、英语的分数很低;分类2则恰恰相反。从中,可以得到规则:物理、数学和化学这三门学科是有相关性的,这三门学科相互促进,而与语文、历史、英语三门学科相排斥。
分类1中的学生
序列聚类
新闻网站需要根据访问者在网页上的点击行为来设计网站的导航方式。通过聚类算法可以发现网页浏览者的行为模式,比如识别出了一类浏览者的行为:喜欢察看体育新闻和政治新闻。但浏览者访问网页是有顺序的,先浏览体育新闻再浏览政治新闻,与先浏览政治新闻再浏览体育新闻是两种不同的行为模式,当一个浏览者在浏览体育新闻时,需要预测他下一步会访问哪个网页。
超市里也需要识别顾客购物的顺序,比如发现一类购物顺序是:尿布——奶瓶——婴儿手推车——幼儿玩具,当一个顾客购买了尿布的时候,就可以陆续向顾客寄发奶瓶、婴儿手推车、幼儿玩具的传单。
序列聚类通过对一系列事件发生的顺序聚类,来预测当一个事件发生时,下一步会发生什么事件。
关联
在客户的一个订单中,包含了多种产品,这些产品是有关联的。比如购买了轮胎的外胎就会购买内胎;购买了羽毛球拍,就会购买羽毛球。
关联分析能够识别出相互关联的事件,预测一个事件发生时有多大的概率发生另一个事件。