Hbase的架构及读写流程
Hbase:
是一个构建在Hdfs基础之上的非关系型数据库。**
是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,目标是存储并计算大型的数据,具体来说就是在非常普通的硬件配置,就能够处理成千上万的行和列组成的大型数据。
关系型数据库和非关系型数库的明显区别:Nosql往往使用api操作,关系型数据习惯与使用sql语句操作
特点:
1.海量存储 -->基于Hdfs
2.列式存储
3.极易扩展
(1)添加datanode机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力;
(2)添加RegionServer机器,提升Hbase上层的处理能力,提升Hbase服务更多Region的能力。
4.高并发
5.稀疏
由于采取列式存储,某一列没有数据不会占有磁盘空间,所有说是稀疏的
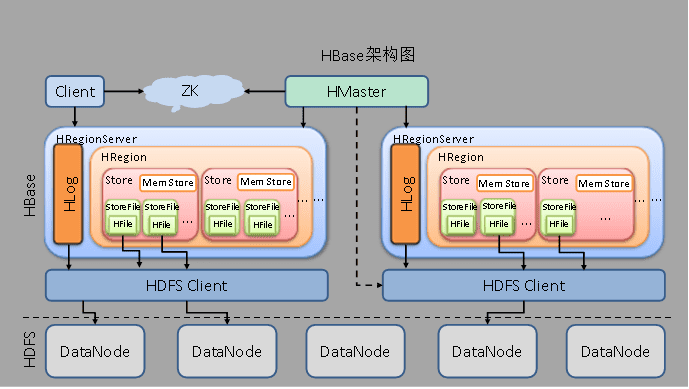
Hbase的架构:
Hbase的相关组件
client:包含访问Hbase的接口,还维护对应的cache来加速对Hbase的访问(如缓存.META元数据信息)
Zookeeper:维护master的高可用,RegionServer的监控,元数据的入口以及集群配置的维护
Hmaster:为RegionServer分配Region、维护集群的负载均衡、元数据信息、将失效的Region分配到正常的RegionServer上、当RegionServer失效,协调对应Hlog的拆分
HRegionServer:对接用户的读写请求、管理master为其分配的Region、与HDFS交互,将数据存储到HDFS上、负责Region变大后的拆分以及StoreFile的合并工作
HDFS:提供元数据和表数据的底层分布式存储服务、多副本保证可靠性和高可用性
**其他组件:**
Write-Ahead logs(WAL,HLOG&edits日志)
Region:Hbase表的分片
Store:对应Hbase中的一个列族
MemStore:内存存储
StoreFile/HFile:不同时期对实际存储文件的不同叫法
Hbase中的角色:
Hmaster:
1.监控RegionServer
2.处理RegionServer故障转移
3.处理元数据的变更
4.处理region的分配或转移
5.在空闲时间进行数据的负载均衡
6.通过Zookeeper发布元数据的位置给客户端
RegionServer:
1.负责存储HBase的实际数据
2.处理分配给它的Region
3.刷新缓存到HDFS
4.维护Hlog(每个regionserver都有一个Hlog)
5.执行压缩
6.负责处理Region分片(自动分片)
Hbase的读写原理
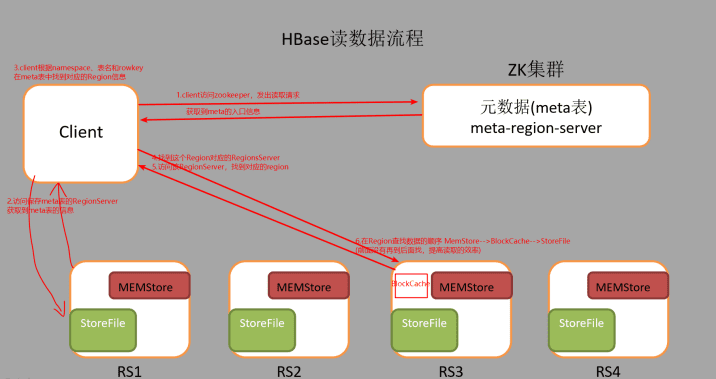
读流程:
1.client先访问zookeeper,得到zookeeper中保存的meta表所在的RegionServer位置信息
2.访问从zookeeper得到的保存meta表的RegionServer从而获取meta表的信息
3.client根据namespace、表名和rowkey在meta表中找到对应的Region信息
4.找到这个Region对应的RegionsServer
5.访问这个RegionServer,找到对应的region
6.在Region查找数据的顺序 MemStore-->BlockCache-->StoreFile(前面没有再到后面找,提高读取的效率)
7.如果是从StoreFile读取的数据,首先写入BlockCache中然后在返回给客户端
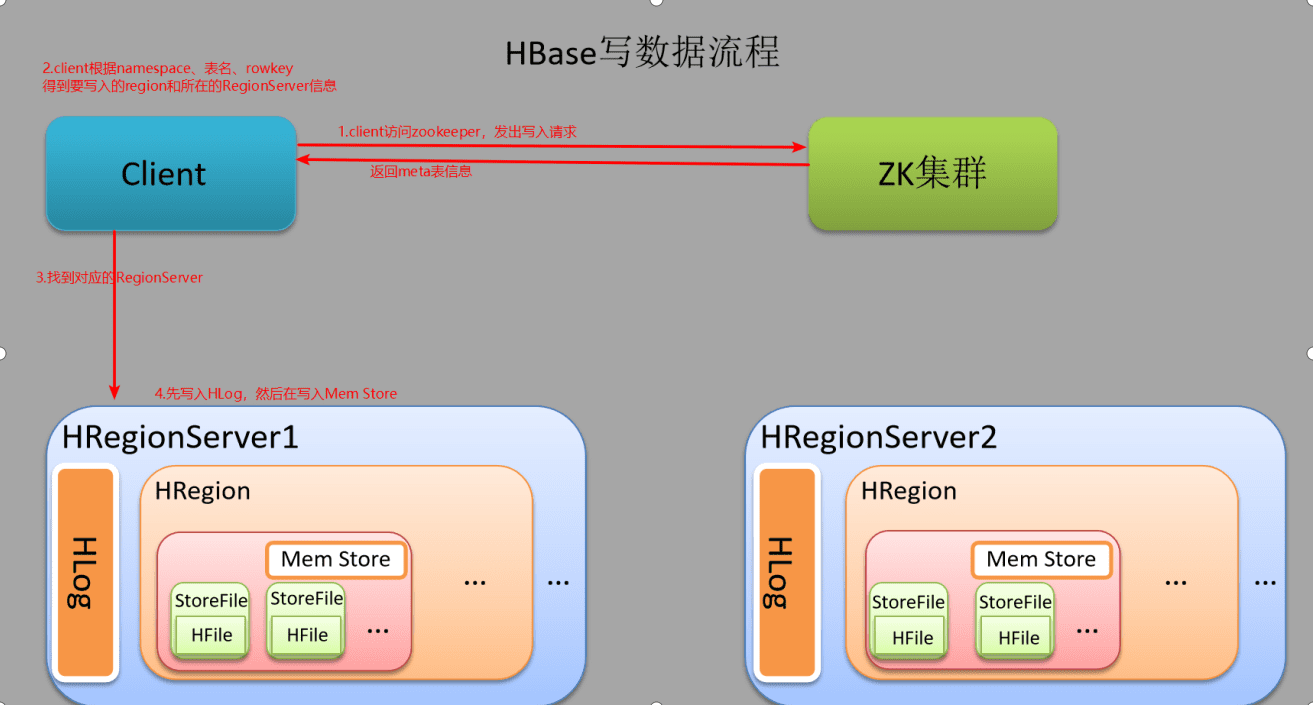
写流程:
1.client先访问zookeeper,从meta表获取对应的region信息,然后找到meta表的数据
2.根据namespace、表名和rowkey在meta表的数据找到写入数据对应的region信息
3.找到对应的RegionServer和和要写入的region
4.将数据先写入HLog(WAL,write ahead log),然后在写入MemStore。为了数据的持久化和恢复
数据flush过程:
当MemStore数据达到阈值(默认128M),将数据刷新到磁盘,清空内存中的数据,同时删除HLog中的历史数据
1.hbase.hregion.memstore.flush.size: 针对region级别,当一个region内地所有memstore的总大小达到阈值的时候,所有memstore中的数据溢写到磁盘
2.hbase.regionserver.global.memstore.size:针对RegionServer级别,当一个RegionServer内的所有memstore总大小达到阈值,当前regionserver内所有store的memstore全部flush
数据合并过程:
1.当一个store(也就是一个列组)中的Hfile的数据快达到4快,HMaster将数据块加载到本地,进行合并;
2.当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的HRegionServer管理(一个store列族数据超过256M会对整个region进行切分,此处可以预分区)
3.自动切分region
4.当HRegionServer宕机后,将HRegionServer上的HLog进行查分,然后分配给不同的HregionServer加载,修改.META